What is a Clustered Index Scan
 Christopher Martinez
Christopher Martinez We can say, a Clustered Index Scan is same like a Table Scan operation i.e. entire index is traversed row by row to return the data set. … If the SQL Server optimizer determines there are so many rows need to be returned it is quicker to scan all rows than to use index keys.
What is Clustered index Scan?
We can say, a Clustered Index Scan is same like a Table Scan operation i.e. entire index is traversed row by row to return the data set. … If the SQL Server optimizer determines there are so many rows need to be returned it is quicker to scan all rows than to use index keys.
What is the difference between clustered index seek and scan?
A scan is the opposite of a seek, where a seek uses the index to pinpoint the records that are needed to satisfy the query. … Since this table has a clustered index and there is not a WHERE clause SQL Server scans the entire clustered index to return all rows.
Is a clustered index scan good or bad?
Clustered index scan Good or bad: If I had to make a decision whether it is a good or bad, it could be a bad. Unless a large number of rows, with many columns and rows, are retrieved from that particular table, a Clustered Index Scan, can degrade performance.How does Clustered index Scan improve performance?
- don’t use SELECT * – that’ll always have to go back to the clustered index to get the full data page; use a SELECT that explicitly specifies which columns to use.
- if ever possible, try to find a way to have a covering nonclustered index, e.g. an index that contains all the columns needed to satisfy the query.
Is index scan better than table scan?
3) index scan is faster than a table scan because they look at sorted data and query optimizers know when to stop and look for another range. 4) index seek is the fastest way to retrieve data and it comes into the picture when your search criterion is very specific.
What causes Clustered index Scan?
you’ve requested rows directly in the query that’s why you got a clustered index SEEK . Clustered index scan: When Sql server reads through for the Row(s) from top to bottom in the clustered index. for example searching data in non key column.
How do I fix Clustered index Seek?
- evict all varlenght into a separate allocation unit by setting ‘large value types out of row’ to 1 and recreating the table from scratch).
- enable page compression (SQL 2008 EE only).
Is full table scan always bad?
No row-source operation is good or bad in itself. Each is the best choice in some contexts. A full-table scan (FTS) is faster than index access in the following situations. … If reading right through the table would be less effort than retrieving rows by probing an index, then FTS is actually the better choice.
How do I stop table scanning?- Avoiding table scans of large tables.
- Index, Index, Index.
- Create useful indexes.
- Make sure indexes are being used, and rebuild them.
- Think about index order.
- Think About Join Order.
- Decide Whether a Descending Index Would Be Useful.
- Prevent the user from issuing expensive queries.
Which is faster clustered or non clustered index?
If you want to select only the index value that is used to create and index, non-clustered indexes are faster. For example, if you have created an index on the “name” column and you want to select only the name, non-clustered indexes will quickly return the name.
Why is SQL using an index scan instead of seek?
2 Answers. It is because it is expecting close to 10K records to return from the matches. To go back to the data to retrieve other columns using 10K keys is equivalent to something like the performance of just scanning 100K records (at the very least) and filtering using hash match.
Which is faster index scan or index seek?
Note however that in certain situations an index scan can be faster than an index seek (sometimes significantly faster) – usually when the table is very small, or when a large percentage of the records match the predicate.
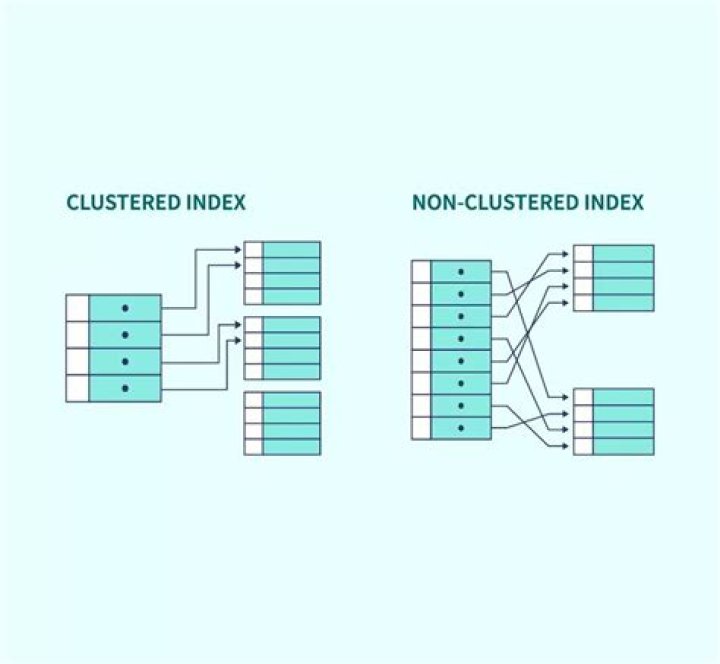
What is clustered and non clustered index?
A Clustered index is a type of index in which table records are physically reordered to match the index. A Non-Clustered index is a special type of index in which logical order of index does not match physical stored order of the rows on disk.
What is non Clustered index Scan?
1. 13. As the name suggests, Non Clustered Index Scans are scans on Non Clustered Indexes – NCI scans will typically be done if all of the fields in a select can be fulfilled from a non clustered index, but where the selectivity or indexing of the query is too poor to result in an Seek.
Is table scan bad?
A table scan is the reading of every row in a table and is caused by queries that don’t properly use indexes. Table scans on large tables take an excessive amount of time and cause performance problems.
What is an index only scan?
Index-only scans are a major performance feature added to Postgres 9.2. They allow certain types of queries to be satisfied just by retrieving data from indexes, and not from tables. This can result in a significant reduction in the amount of I/O necessary to satisfy queries.
When a table has a clustered index the query performs which type of execution?
Merge join is performed when matching rows from two sorted input tables exploit their sorting order. In simple words when both tables have clustered index and we use them in join to get data then a Sql optimizer chooses the merge operator to execute a query.
How do I optimize a full table scan?
Parallel Query: Oracle parallel query is the best way to optimizer a full-table scan and a full-table scan on a server with 32 CPU’s will run more than 30x faster than a non-parallelized full-table scan. The trick when optimizing full table scans with parallel query is finding the optimal “degree” of parallelism.
How can I improve my full table scan?
Make sure that full table scans are the bottleneck before you spend a lot of time doing something that may only improve performance by 1%. Parallelism SELECT /*+ PARALLEL */ * FROM Table1; Parallelism can easily improve full table scan performance by an order of magnitude on many systems.
What is Storage full in explain plan?
It refers to Exadata’s Smart Scan and cell offload capability – that part of the plan is being passed down to the storage tier which executes that part of the query.
What is subquery SQL w3schools?
Subquery or Inner query or Nested query is a query in a query. SQL subquery is usually added in the WHERE Clause of the SQL statement. Most of the time, a subquery is used when you know how to search for a value using a SELECT statement, but do not know the exact value in the database.
What is full index scan in MySQL?
A full index scan is where Oracle reads the data from the index, and the index is in the order required by the query. … This type of scan happens when the data in the index is in no particular order.
What is a cross join MySQL?
In MySQL, the CROSS JOIN produced a result set which is the product of rows of two associated tables when no WHERE clause is used with CROSS JOIN. In MySQL, the CROSS JOIN behaves like JOIN and INNER JOIN of without using any condition. …
How do you stop a full index scan?
To get an execution plan that avoids a full scan, MySQL would need an index that has from_date as the leading column. Optimally, the index would contain all of the other columns referenced in the query, to avoid looking up values in the underlying data pages.
What does exists construct test in SQL?
The EXISTS operator is used to test for the existence of any record in a subquery. The EXISTS operator returns TRUE if the subquery returns one or more records.
Does a clustered index improve performance?
Effective Clustered Indexes can often improve the performance of many operations on a SQL Server table. … To be clear, having a non-clustered index along with the clustered index on the same columns will degrade performance of updates, inserts, and deletes, and it will take additional space on the disk.
Do I need a clustered index?
As a rule of thumb, every table should have a clustered index. Generally, but not always, the clustered index should be on a column that monotonically increases–such as an identity column, or some other column where the value is increasing–and is unique. … With few exceptions, every table should have a clustered index.
Does clustered index take up space?
The clustered index does not take as much space as the non-clustered index does because the non clustered index are stored in a separate space on the disk.
How do I create a clustered index in SQL?
On the Table Designer menu, click Indexes/Keys. In the Indexes/Keys dialog box, click Add. Select the new index in the Selected Primary/Unique Key or Index text box. In the grid, select Create as Clustered, and choose Yes from the drop-down list to the right of the property.
What is clustered index with example?
A clustered index defines the order in which data is physically stored in a table. Table data can be sorted in only way, therefore, there can be only one clustered index per table. In SQL Server, the primary key constraint automatically creates a clustered index on that particular column.