Is decision tree supervised learning
 Christopher Martinez
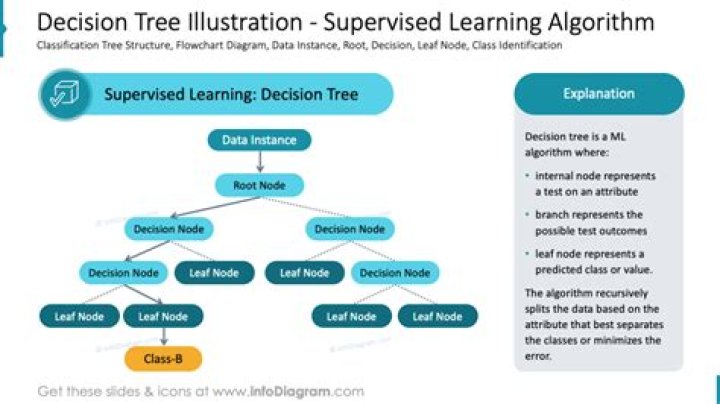
Christopher Martinez Introduction Decision Trees are a type of Supervised Machine Learning (that is you explain what the input is and what the corresponding output is in the training data) where the data is continuously split according to a certain parameter. The tree can be explained by two entities, namely decision nodes and leaves.
Is decision tree a supervised method?
Decision Trees (DTs) are a non-parametric supervised learning method used for classification and regression.
Why is decision tree supervised?
Decision Trees (DTs) are a supervised learning technique that predict values of responses by learning decision rules derived from features. … These models learn the features directly from the data, rather than being prespecified, as in some other basis expansions.
Is decision tree an unsupervised learning algorithm?
Decision Tree is a Supervised learning technique that can be used for both classification and Regression problems, but mostly it is preferred for solving Classification problems.Is Decision Tree case based learning?
Our random decision tree (RDT) algorithm is an example of a general approach to combining machine learning methods with case-based reasoning. … The cases within the circle are retrieved as the closest neighbors of the marked case, and are used to train an independent learning algorithm.
Are Decision Trees binary?
A Binary Decision Tree is a structure based on a sequential decision process. Starting from the root, a feature is evaluated and one of the two branches is selected. This procedure is repeated until a final leaf is reached, which normally represents the classification target you’re looking for.
Which of the following is not supervised learning?
Unsupervised learning Unsupervised learning is a type of machine learning task where you only have to insert the input data (X) and no corresponding output variables are needed (or not known). It does not have labeled data for training.
Is decision Tree a classification algorithm?
Classification is a two-step process, learning step and prediction step, in machine learning. In the learning step, the model is developed based on given training data. … Decision Tree is one of the easiest and popular classification algorithms to understand and interpret.Is classification Tree supervised or unsupervised?
Decision Trees are a non-parametric supervised learning method used for both classification and regression tasks. Tree models where the target variable can take a discrete set of values are called classification trees.
Is linear regression supervised or unsupervised?Linear Regression is a machine learning algorithm based on supervised learning. It performs a regression task. Regression models a target prediction value based on independent variables. It is mostly used for finding out the relationship between variables and forecasting.
Article first time published onIs clustering supervised learning?
Clustering is a powerful machine learning tool for detecting structures in datasets. … Unlike supervised methods, clustering is an unsupervised method that works on datasets in which there is no outcome (target) variable nor is anything known about the relationship between the observations, that is, unlabeled data.
What is the difference between supervised & unsupervised learning?
The main difference between supervised and unsupervised learning: Labeled data. The main distinction between the two approaches is the use of labeled datasets. To put it simply, supervised learning uses labeled input and output data, while an unsupervised learning algorithm does not.
Is cart supervised or unsupervised?
CART is a supervised learning technique, since it is provided a labeled training dataset in order to construct the classification or regression tree model.
What is supervised learning algorithm?
A supervised learning algorithm takes a known set of input data (the learning set) and known responses to the data (the output), and forms a model to generate reasonable predictions for the response to the new input data. Use supervised learning if you have existing data for the output you are trying to predict.
What is the example of case based learning?
Examples. Humanities – Students consider a case that presents a theater facing financial and management difficulties. They apply business and theater principles learned in the classroom to the case, working together to create solutions for the theater.
What is the difference between a classification tree and a decision tree?
The regression and classification trees are machine-learning methods to building the prediction models from specific datasets. … The primary difference between classification and regression decision trees is that, the classification decision trees are built with unordered values with dependent variables.
What are decision trees commonly used for?
A Decision Tree is a supervised machine learning algorithm that can be used for both Regression and Classification problem statements. It divides the complete dataset into smaller subsets while at the same time an associated Decision Tree is incrementally developed.
What are the types of supervised learning?
- Regression. In regression, a single output value is produced using training data. …
- Classification. It involves grouping the data into classes. …
- Naive Bayesian Model. …
- Random Forest Model. …
- Neural Networks. …
- Support Vector Machines.
Which one of these is a tree based learner?
Q.Which one of these is a tree based learner?B.bayesian belief networkC.bayesian classifierD.random forestAnswer» d. random forest
Can Decision Trees be used for all classification tasks?
Decision Trees can be used for Classification Tasks. Explanation: None.
Can Decision Trees be used for binary classification tasks?
Explanation: Decision Trees can be used for Classification Tasks.
How are Decision Trees used in classification?
Decision Tree – Classification. Decision tree builds classification or regression models in the form of a tree structure. It breaks down a dataset into smaller and smaller subsets while at the same time an associated decision tree is incrementally developed. … Decision trees can handle both categorical and numerical data …
Is decision tree parametric or non parametric?
A decision tree is a non-parametric supervised learning algorithm used for classification and regression problems. It is also often used for pattern analysis in data mining. It is a graphical, inverted tree-like representation of all possible solutions to a decision rule/condition.
What is difference between decision tree and random forest?
A decision tree combines some decisions, whereas a random forest combines several decision trees. Thus, it is a long process, yet slow. Whereas, a decision tree is fast and operates easily on large data sets, especially the linear one. The random forest model needs rigorous training.
Which algorithm is used in decision tree?
The decision tree learning algorithm The basic algorithm used in decision trees is known as the ID3 (by Quinlan) algorithm. The ID3 algorithm builds decision trees using a top-down, greedy approach.
Is linear regression supervised learning?
Yes, Linear regression is a supervised learning algorithm because it uses true labels for training. Supervised learning algorithm should have input variable (x) and an output variable (Y) for each example.
Is Random Forest supervised learning?
Random forest is a supervised learning algorithm. The “forest” it builds, is an ensemble of decision trees, usually trained with the “bagging” method. The general idea of the bagging method is that a combination of learning models increases the overall result.
Is K-means supervised or unsupervised?
K-Means clustering is an unsupervised learning algorithm. There is no labeled data for this clustering, unlike in supervised learning. K-Means performs the division of objects into clusters that share similarities and are dissimilar to the objects belonging to another cluster.
Can regression be used for unsupervised learning?
In contrast to supervised learning, we cannot apply unsupervised methods to classification or regression style problems. … Essentially, our unsupervised learning algorithm will find the hidden patterns or groupings within the data without the need for a human (or anybody) to label the data or intervene in any other way.
What is regression tree in machine learning?
A regression tree is basically a decision tree that is used for the task of regression which can be used to predict continuous valued outputs instead of discrete outputs.
Can decision trees be used for performing clustering?
Decision trees are mainly used to perform classification tasks. Samples are submitted to a test in each node of the tree and guided through the tree based on the result. Decision trees can also be used to perform clustering, with a few adjustments. … Decision trees are well-known tools to solve classification problems.